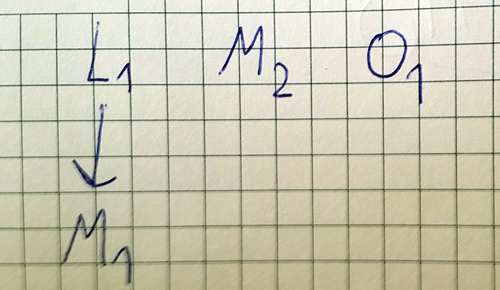Myślę, że warto dla tego nietrywialnego zagadnienia założyć wątek, zwłaszcza, że mam wątpliwości co do nie których aspektów agregacji.
Motywacja
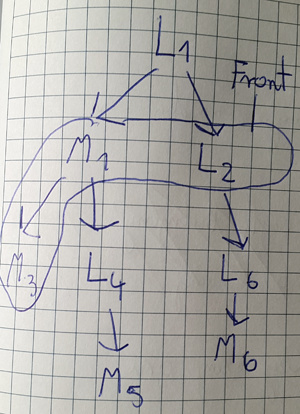
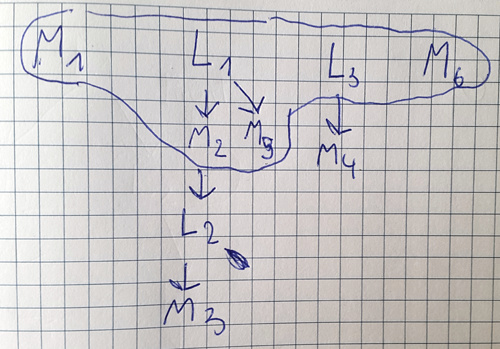
Stary Sealious nie posiada właściwych implementacji get_pre_aggregation_stage dla strategii dostępu and oraz or i chcemy to zmienić - jest duża szansa, że będzie to można wykorzystać w nowej wersji frameworka. Problem polega na tym, że and oraz or mogą przyjąć wiele strategii dostępu AS z wieloma lookupami i matchami, które mogą się powtarzać w różnych AS. W ramach optymalizacji każdy $match chcemy wykonać możliwie najwcześniej, a $lookup jak najpóźniej. Doszliśmy do wniosku, że problem sprowadza się do acyklicznego grafu zależności - trzeba będzie zbudować graf, zapuścić jakiś algorytm i powinno zadziałać ![]()
Zarys implementacji
Chcemy zakryć szczegóły implementacji obiektami Query zdefiniowanymi następująco:
lookup()match()-
execute()- to jeszcze do ustalenia, bo może wolimy zewnętrzną funkcjęexecute_query(query)
Zatem przykładowy kod może wyglądać następująco:
const query = new Query("books");
query.lookup({
from: "numbers",
localField: "body.number",
foreignField: "sealious_id",
as: "number",
});
query.match({ "number._id": { $exists: true } });
query.execute();
Wątpliwości
- czy sytuacja kiedy najpierw zostanie wywołany
matchna jakimś fieldzie, a dopiero późniejlookupzasz tym fieldem jest błędem? - co jeżeli ponownie wywoływany jest
lookupz takimi samymifrom,localFieldiforeignField, ale z innymas? Chyba można by wtedy dokonać konwersji nazwy pola na danym lookupie i matchach odwołujących się do nowej nazwy, tylko pytanie czy warto.